




Convolutional neural networks, usually referred to as ConvNets or CNNs, are a type of deep neural network that has shown to be effective in the field of computer vision. They're employed in a variety of applications, including facial identification, medical imaging, and self-driving cars.
This article describes how convolutional neural networks function and shows how to use TensorFlow and Keras to apply them to picture categorization. The following are the two main sections of the article:
- Convolutional Neural Network Architecture
- TensorFlow and Keras are used to create a rudimentary CNN model.
Convolutional Neural Network Architecture
Convolutional Neural Networks (CNNs) are a type of deep neural network that can recognise spatial connections in images. A two-dimensional picture (a matrix of pixel values) is collapsed (i.e. flattened) into a one-dimensional vector and fed into a dense network in typical feed forward neural networks. As a result, the two-dimensional image's structure is lost, and the image's spatial organisation is lost as well. Furthermore, because every pixel in the image is coupled to every neuron in the network, this necessitates costly computations, resulting in a large number of parameters.

The architecture of the Convolutional Neural Network addresses the above concerns by using the convolution and pooling layers described below.

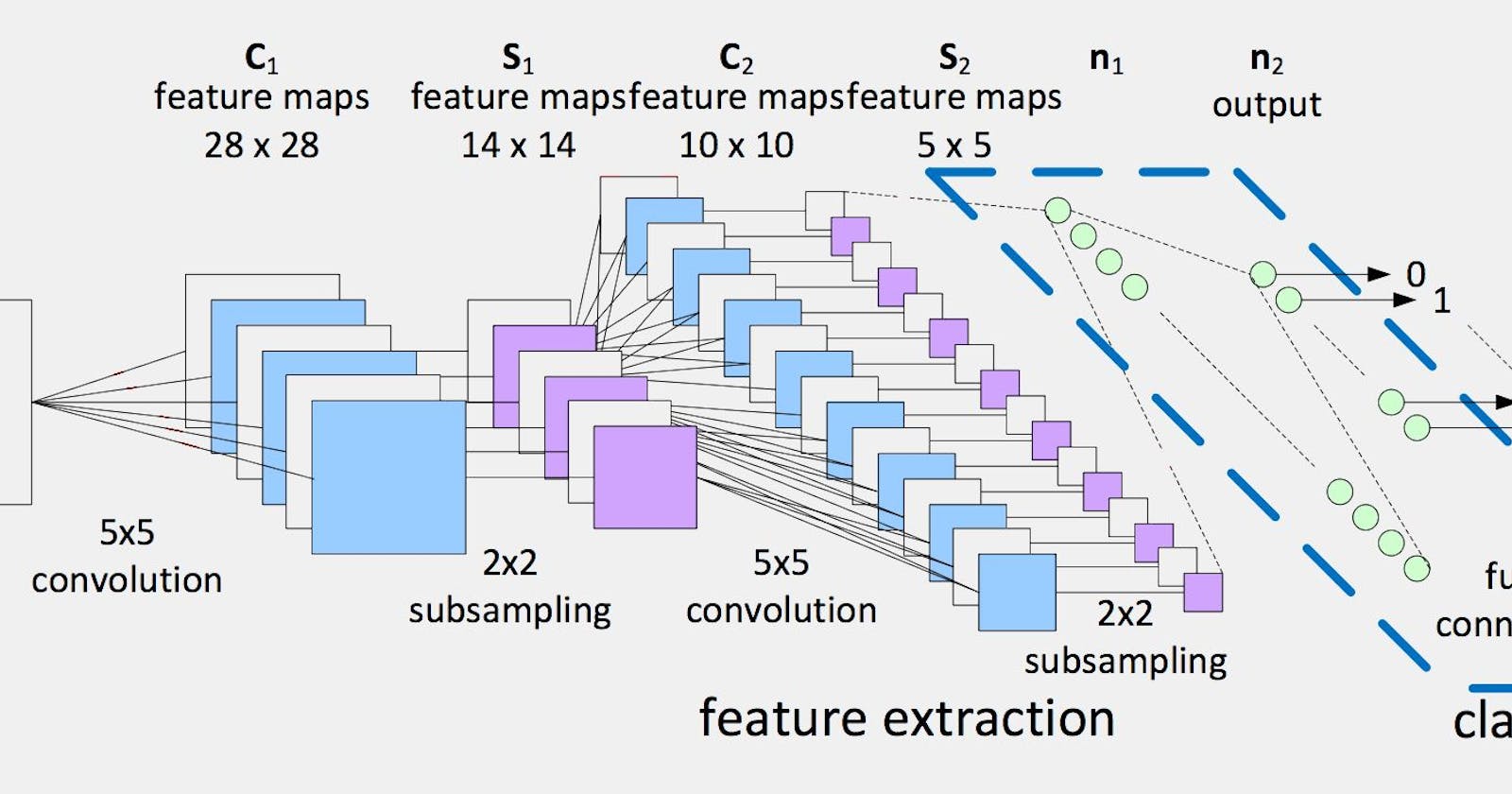
Layer of Convolution
In a convolutional neural network, the convolution layer is the first and most critical layer. It uses a technique known as 'convolution' to extract features without having to manually extract them. To create a feature map, the convolution operation is applied between a specified filter (also known as a kernel) and a specific patch of the picture. A filter is made up of a set of weights that are convolved with the image. The filter detects certain patterns in an image, such as edges, and it comes in a variety of sizes; the most common filter sizes are 3x3, 5x5, and 7x7.

The following formula can be used to calculate the size of the generated feature map: W is the input volume, K is the kernel size, P is the amount of padding added, and S is the stride. Padding is the process of padding an input image with zeros around the border in order to adjust the output size. The number of pixels by which the filter convolves over a certain image is referred to as a stride. W is 9, K is 3, S is 1, and P is 0, resulting in a 7x7x1 feature map.

It's worth noting that the convolutional layer, in reality, has several filters and hence produces one feature map per filter. In addition, input images are made up of many layers (one per colour layer). RGB photos, for example, have three channels, one for each colour (red, green, and blue), whereas grayscale images only have one. The image in Figure 3 is 9x9x1, which means it is a 9x9 pixel grayscale image.
The ReLU activation function is used after the convolution procedure to create non-linearity and replace all non-negative values with zeros.
Layer of Pooling
After the convolution layer follows the pooling layer. Its job is to shrink the convolved image's spatial size and extract prominent features. There are two types of pooling that are commonly used:
- The maximum value of the patch covered by the kernel is returned by max pooling.
- The average value of the patch covered by the kernel is returned by average pooling.

Layer with a complete connection
The fully connected layer is placed after the convolution and pooling layers. Simply said, the fully connected layer is a feed forward neural network that does categorization. The final output of the pooling or convolution layer flattened into a 1D array is the input of the fully linked layer (i.e. vector).
TensorFlow and Keras Model for CNN
The key layers of the convolution neural network were highlighted and their functions were outlined in the preceding section. This section explains how to use TensorFlow and Keras to create a CNN model.
There are three methods for creating a model (sequential, functional and model subclassing). A model produced using the sequential method is shown in Figure 6. This is a simple CNN model that was used to categorise photos of dogs and cats with an accuracy of roughly 90% across 100 epochs.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input shape=(150,150, 3)) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(256, (3,3), activation='relu' ) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid' )
])
Let's have a look at the model one layer at a time:
A total of 64 3x3 filters are used in the first layer. Stride and padding are set to their default settings, which are (1,1) for stride and 'valid' for padding (meaning that no padding is applied). If padding is to be used, it should be the'same' padding. Because the image is 150x150 pixels and includes three channels, the input shape is (150, 150, 3). (i.e. RGB).
Then, with a pool size of 2x2, the max pooling layer is implemented.
One convolutional layer is followed by a max pooling layer, which is repeated twice. The number of layers is a controllable hyper-parameter. The number of filters increases as we progress further into the convolution layers; this aids in capturing as many permutations as possible from low-level features (e.g., vertical lines, small circles, etc.) in order to generate high-level feature abstractions. Doubling the number of filters is a popular technique.
The completely connected network, which is made up of two dense layers, follows. The inputs are flattened since the dense network requires a 1D array of features. The first dense layer is made up of 1024 units and uses the activation function 'relu'. Because the problem being addressed is a binary classification problem, the second and final dense layer is made up of a single unit (i.e. output) with the activation function 'sigmoid'.
Natural language processing, speech recognition, and computer vision have all benefited from convolutional neural networks. They are most known for their performance in image categorization tasks. This post discussed the fundamentals of convolutional neural network design with a focus on picture classification, as well as a demonstration of how to build a CNN model with TensorFlow and Keras.
References: MIT 6.S191 (2020): Convolutional Neural Networks